Note: I've tried to make sure this website can be used with JS disabled, but some of the articles use MathJax to display math formulas. Those formulas will sadly be displayed as LaTeX code if your browser has JavaScript disabled.
I've been wanting to have some view statistics for my blog for a long time, mainly to answer the question: "Am I writing for 5, 50, 500 people?".
However, I've never liked the idea of relying on external services, especially if they used cookies to track visitors.
So a few days ago I decided to go into full "I'll do it myself" mode and implement a small Rust utility to parse nginx access log files and generate some graphs out of them. After a few days tweaking the tool and seeing what stats I could get out of it, I gotta say I'm quite happy with this tool :)
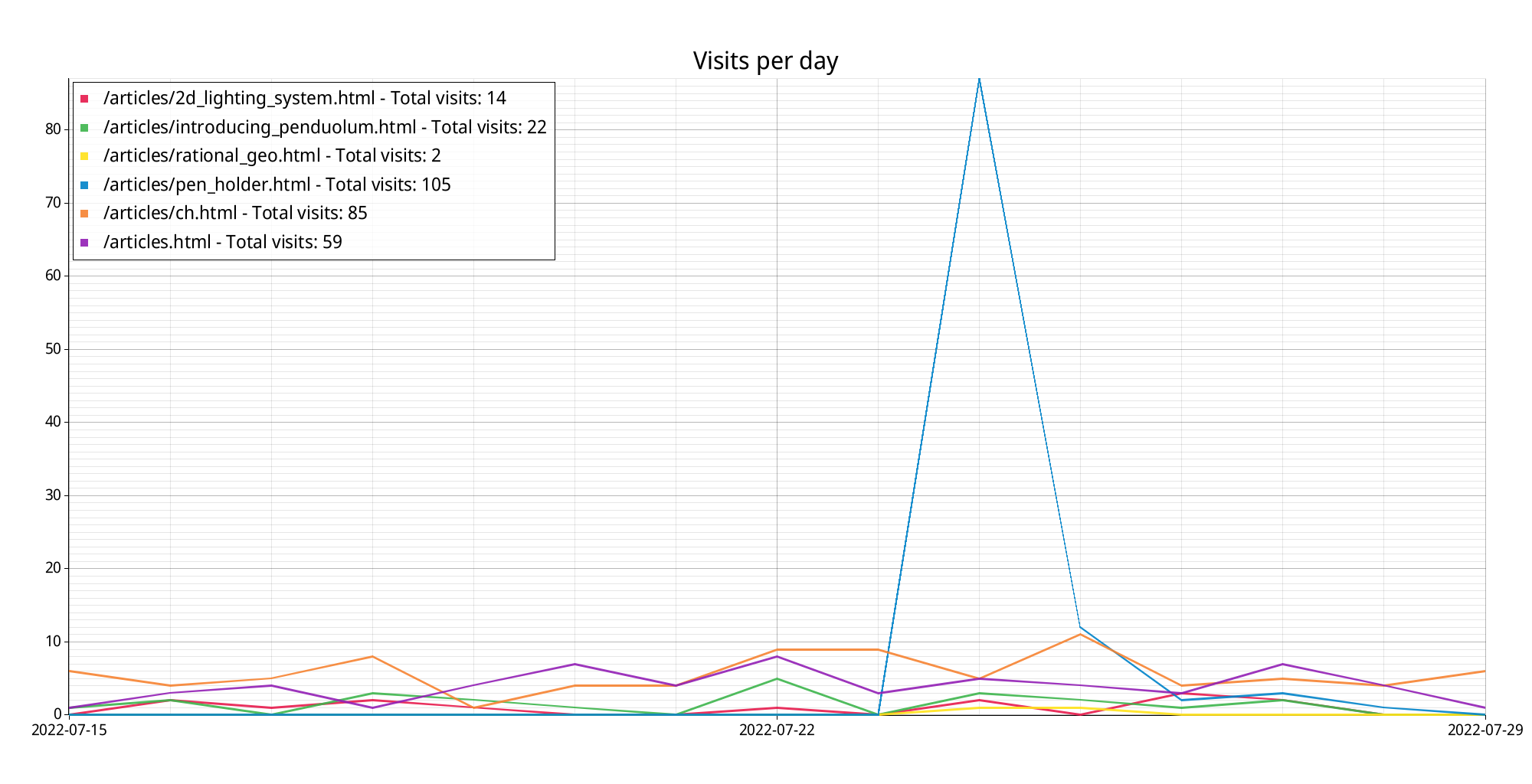
It generates images like this:
In that image we can see a few things.
First, there's a big spike from when I posted the pen holder article. I only posted it on Twitter and didn't get much movement there, so I guess that's why the spike has such a sharp decline.
And second, there's a steady trickle of people somehow finding my blog and reading some stuff in it. I'm assuming the circular harmonics article is the main driver behind that, given the views it gets. It's nice knowing people liked that one!
Anyway, with this tool I'm happy that:
The code itself is very hardcoded to my blog so I don't think it'd be very useful for other people, but I can share the general structure so anyone can build a similar tool for themselves. Mine is ~300 lines long including the graph drawing, so it shouldn't take long to build a clone :-)
Rust crates used:
The general flow is:
One slightly more involved thing I had to do was parse the nginx logs. They're full of malicious requests, so they're a bit of a sensitive thing, but this snippet of code seems to be robust enough to handle the non-malicious requests and more or less cope with the bad ones. It's not particularly optimized (it does string copying everywhere), but it's fast enough that the whole script handles 160K log lines in <5 seconds in my laptop, so... good enough for me!
Also, I make no claims that this is a perfect, or even decent parser. It's just something I whipped up in 45 minutes and seems to work well enough for the logs I have.
// Log format:
// 66.249.76.149 - - [28/Jul/2022:08:37:26 +0000] "GET / HTTP/1.1" 301 169 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
fn sanitize_request(req: &str) -> String {
let splits = req.split(' ');
let url_split = splits.skip(1).next(); // Skip the http method (GET, POST...) and ignore the HTTP version at the end
if url_split.is_some() {
String::from(url_split.unwrap())
} else {
result
}
}
fn tokenize_log_line(line: &str) -> Vec<String> {
let mut result = vec![];
let mut cs = line.chars();
let mut current_token = String::new();
let mut token_delimiter = None;
loop {
let ch = cs.next();
if ch.is_none() {
break;
}
let c = ch.unwrap();
if current_token.is_empty() && token_delimiter.is_none() {
// Read starting char
match c {
'"' => token_delimiter = Some('"'),
'[' => token_delimiter = Some(']'),
' ' => {} // Ignore spaces
'\t' => {} // Ignore tabs
_ => {
token_delimiter = Some(' ');
current_token.push(c);
}
}
} else {
if Some(c) == token_delimiter {
// Finish the token
result.push(current_token);
current_token = String::new();
token_delimiter = None;
} else {
current_token.push(c);
}
}
}
// TODO -- If current_token isn't empty here, that should be an error
result
}
struct LogEvent {
// ip: String,
timestamp: chrono::DateTime<FixedOffset>,
request: String,
status: u16,
// bytes: u32,
referrer: String,
user_agent: String,
}
impl LogEvent {
fn from_str(line: &str) -> Result<Self> {
let tokens = tokenize_log_line(line);
macro_rules! try_token {
($index: expr, $name: expr) => { {
if tokens.len() <= $index {
return Err(anyhow::anyhow!(
"line doesn't have enough tokens for {}: {}",
$name,
line
));
}
tokens[$index].clone()
} };
}
Ok(LogEvent {
//ip: try_token!(0usize, "ip"),
timestamp: chrono::DateTime::parse_from_str(
&try_token!(3usize, "timestamp"),
"%d/%h/%Y:%H:%M:%S %z",
)?,
request: sanitize_request(&try_token!(4, "request")),
status: u16::from_str_radix(&try_token!(5, "status"), 10)?,
// bytes: u32::from_str_radix(&try_token!(6, "bytes"), 10)?,
referrer: try_token!(7, "referrer"),
user_agent: try_token!(8, "request"),
})
}
}